
The path from AI pilot to production is structural, not technical, and the companies clearing it in 2026 are doing so by following an architecture pattern that turns pilot environments into the foundation for scaled deployment, not a separate experiment that has to be migrated later. Here is the RevOps blueprint Mountainise applies to move enterprise AI out of pilot purgatory and into production at scale. Yallo
What is AI pilot purgatory?
AI pilot purgatory is the state where enterprise AI projects work in a controlled environment but stall before reaching production deployment, often for six months or more. The pilot proves the technology can do the task. The production rollout that should follow never starts, or starts and stalls.
Pilot paralysis comes first. Organizations launch proof-of-concepts in safe sandboxes but often fail to design a clear path to production. The technology works in isolation, but integration challenges, including secure authentication, compliance workflows, and real-user training, remain unaddressed until executives request the go-live date. By the time the production scope is clarified, the foundational decisions that should have been made at pilot scoping are too expensive to revisit, and the project loses momentum. WorkOS
Pilot purgatory is not a technology problem. It is an architecture and sequencing problem. The pilots that escape it are not the ones with better AI. They are the ones whose pilot scope was designed to be the first installment of a production deployment, not a separate event.
Why do enterprise AI pilots stall before production?
Enterprise AI pilots stall before production because the pilot was designed as a demo, not as the first piece of a production system. The pilot answered the question “can the AI do this task?” without answering the harder questions: where will the data come from at scale, who owns the agent after it goes live, how will governance scale, what does the rollback procedure look like, and how does this agent coordinate with the next ten agents the company plans to deploy.
The 12% of pilots that succeed share a different profile. They were scoped against a production architecture from day one. The pilot was a phase of the deployment, not a separate event. Data flowed the way it would flow at scale. Governance applied the way it would apply at scale. The pilot answered “does this work?” while simultaneously building the foundation for the answer “how do we scale this?”
This is the single most common failure pattern Mountainise sees in enterprise AI engagements. Pilots that succeed treat the architecture as the project. Pilots that fail treat the agent as the project.
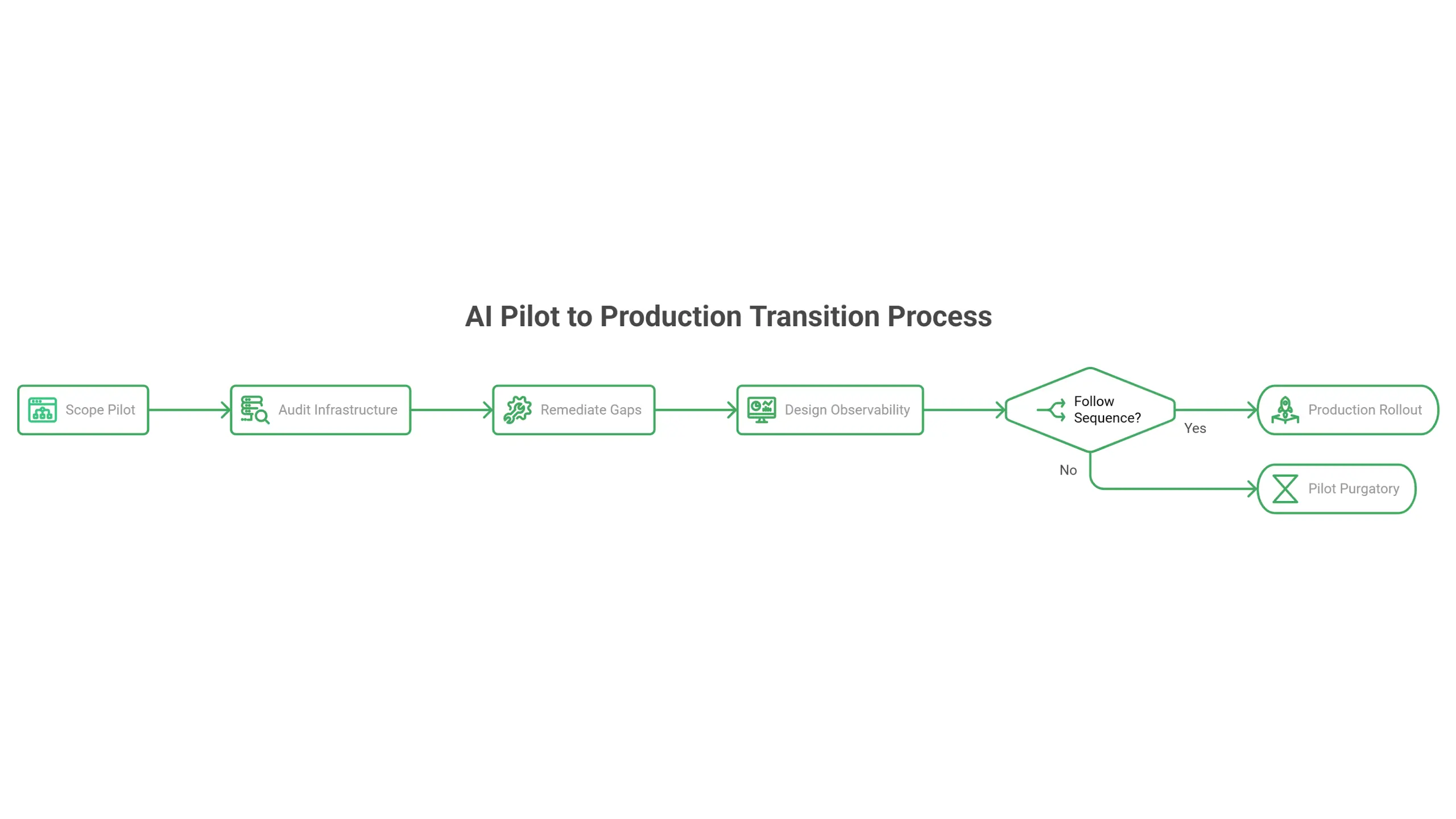
How do you move AI from pilot to production?
To move AI from pilot to production, treat the pilot as the first phase of the production architecture, not as a standalone experiment. The path has four stages: scope the pilot inside the production architecture pattern, audit the RevOps infrastructure that will support the agent at scale, remediate the highest-impact gaps before the pilot ships, and design feedback and observability into the pilot from day one so the production rollout has a working measurement layer.
Mountainise applies this sequence across every enterprise AI engagement. The pilot is never a sandbox. It is the first deployment of a production-grade architecture, narrower in scope but identical in structure. Data flows the way they will flow at scale. Governance applies the way it will apply at scale. Feedback loops are wired in from day one. The pilot answers “does this work?” while simultaneously building the foundation for the answer “how do we scale this?”
The companies that follow this sequence move from pilot to production in 30 to 90 days, depending on the complexity of the use case. The companies that skip the sequence are still in pilot 18 months later.
What is the three-tier architecture for production AI?
The three-tier architecture for production AI is a layered system with three distinct functions: a signal capture layer that ingests data from every revenue-relevant source, an intelligence layer where AI models and orchestration logic live, and an action layer where the agents execute decisions inside the CRM and adjacent systems.
For RevOps teams evaluating implementation, the architecture must be understood as a three-tier system, each layer serving a distinct function in the signal-to-action pipeline. Each tier maps to a specific class of capability and a specific class of failure. The signal capture layer determines what the agent can see. The intelligence layer determines what the agent can reason about. The action layer determines what the agent can do, and what guardrails control the doing. Oliv AI
Most failed enterprise AI rollouts skip one of the three tiers, usually the signal capture layer. The agent is deployed against the CRM directly, with no unifying data layer underneath. The result is the data architecture gap that drives the 88% failure rate, scaled to production.
How does the signal capture layer work?
The signal capture layer works by collecting and unifying raw signals from every revenue-relevant system into a single, governed data model that the AI agent can read from reliably. Customer data from the CRM. Engagement data from the marketing automation platform. Support data from the helpdesk. Product usage data from the application. Billing data from the financial system. Conversation data from email, calls, and meetings.
A complete architecture requires stitching Call, Meeting, Email, Slack, and Support Tickets into a 360-degree account view. Most legacy CRM-only architectures capture one or two channels, typically CRM updates and email. The agent reasoning on top of that partial view will make partial decisions. Oliv AI
The signal capture layer is the foundation that everything else depends on. Without it, the intelligence layer has nothing reliable to reason against, the action layer has no context for its decisions, and the feedback loop has no clean baseline to measure outcomes from. This is why Mountainise’s audit sequence always starts here. Fix the signal capture layer first. Everything else assumes it.
How does the intelligence layer work?
The intelligence layer works by housing the models, reasoning engines, and orchestration logic that turn captured signals into decisions. This is where AI agents live, where fine-tuned LLMs grounded in your company’s data operate, where the rule logic deciding which agent handles which step is defined, and where human-in-the-loop checkpoints sit for high-stakes actions.
The intelligence layer is also where governance is enforced at runtime. Role-based access control determines which agents can read which fields. Audit logging captures every decision. Approval gates intercept actions that exceed defined risk thresholds. This is the layer that turns “an AI made a decision” into “an AI made a decision we can explain, justify, and roll back if needed.”
The intelligence layer is what most vendors are selling when they sell “an AI agent.” The layer is only as useful as the signal capture beneath it and the action layer above it. Buying a great intelligence layer without the other two tiers is the most common mistake in enterprise AI procurement, and the most expensive.
How does the action layer work?
The action layer works by executing the decisions the intelligence layer produces, with the right permissions, the right sequencing, and the right rollback paths in place. This is the layer that writes back to the CRM, triggers workflows, sends emails, books meetings, updates deal stages, escalates to humans, and creates audit records of every action it takes.
Action layer design is where many enterprise AI rollouts fail at the last yard. The intelligence layer made a good decision. The action layer wrote it to the wrong field, triggered a conflicting workflow, exceeded its permission scope, or failed to log the action for downstream attribution. The agent looked smart in the demo and broken in production because the action layer was never properly designed.
The fix is risk-tiered action design. Low-risk actions execute autonomously. Medium-risk actions trigger human-in-the-loop approval. High-risk actions require explicit authorization before execution. Risk-tiered governance with RBAC and human-in-the-loop approval gates prevents CRM write errors before they happen. The action layer is where governance becomes operational reality. Oliv AI
How long does AI pilot to production take?
AI pilot to production takes 30 to 90 days when the architecture is designed correctly from the start, and 12 to 18 months (or never) when the pilot was scoped as a standalone experiment. The difference is not effort. It is sequencing.
A realistic 30-day rollout looks like this: sandbox in Week 1, controlled writes in Week 2, scale decision by Month 1. The precondition for moving at this speed is that the RevOps infrastructure (data architecture, system of record, governance, orchestration, feedback) was audited and remediated before the pilot started. The pilot phase becomes a controlled rollout against a production-ready foundation, not a separate experiment that has to be migrated later. Oliv AI
For most enterprises, the audit and remediation phase takes longer than the deployment phase. That is the right ratio. Spend the time on the foundation. The deployment compounds quickly after.
What does production AI ROI look like?
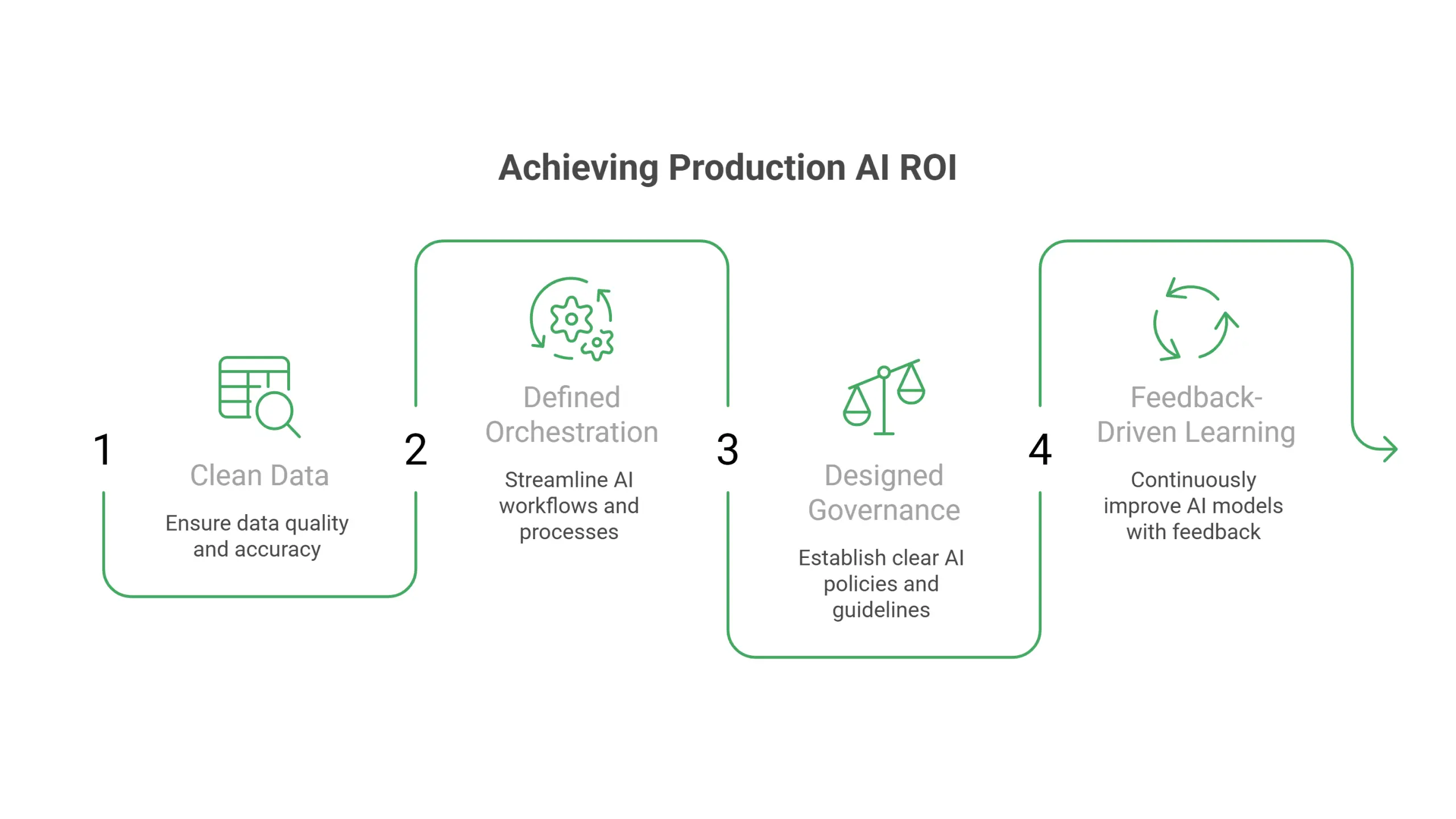
Production AI ROI in enterprise revenue operations looks like measurable lift across forecasting accuracy, pipeline velocity, conversion rates, and rep selling time, with the lift compounding quarter over quarter as agents accumulate learnings from feedback loops. The headline outcomes are well-documented at companies that completed the pilot-to-production transition.
Lumen Technologies projects $50 million in annual savings from AI tools that save their sales team an average of four hours per week. Microsoft reported $500 million in savings from AI deployments in their call centers alone. At the RevOps operational level, the ROI shows up in metrics that compound. AI-driven pipeline intelligence lifts forecast accuracy from 24% to 76% on clean data. Close rates rise by approximately 15% within six months of enrichment implementation, and funnel conversion rates increase by approximately 12%. WorkOS + 2
The pattern across every successful deployment is the same. The AI does not produce the ROI. The combination of clean data, defined orchestration, designed governance, and feedback-driven learning produces the ROI. The AI is what scales the result. The foundation is what makes the result possible.
Take the Next Step: Book a Discovery Call
If your AI pilots are still in purgatory, the diagnosis is rarely the AI. It is the infrastructure underneath. Mountainise’s discovery call walks through the five RevOps infrastructure gaps against your environment specifically, scores your readiness against AI-grade thresholds, and produces a prioritized roadmap that sequences the fix.
The session is built for CROs, VPs of RevOps, COOs, and Heads of Sales and Marketing Operations who have already invested in AI and are ready to move from pilot to production at scale.
If you missed the July 9 webinar (Beyond the Bot: Overcoming the RevOps Infrastructure Gaps Costing Enterprise AI Strategies), the recording is available on request.