
The launch of HubSpot Breeze marks a significant shift for growing mid-market and enterprise teams using the HubSpot Smart CRM. By embedding autonomous intelligence directly into Marketing, Sales, Service, and Content Hubs, Breeze moves the platform away from traditional automation into the era of independent execution.
However, an autonomous tool is entirely dependent on the quality of the ecosystem it occupies. If your HubSpot properties are unstandardized, your object associations are broken, or your third-party integrations are unmanaged, a Breeze agent will quickly scale those operational inefficiencies.
To help your team achieve a predictable rollout, this guide covers the core data, process, and architectural questions required to prepare your CRM for HubSpot Breeze.
What is HubSpot Breeze and what are its core components?
HubSpot Breeze is the native AI engine embedded across the HubSpot Smart CRM suite, consisting of four distinct operational components: Breeze Agents, Breeze Copilot, Breeze Intelligence, and an open platform architecture.
Rather than functioning as a standalone app or an isolated chatbot, Breeze acts as an underlying infrastructure layer that infuses autonomous execution directly into existing GTM workflows.
- Breeze Agents: Completely autonomous software actors designed to execute highly specific, end-to-end operational roles, such as the Prospecting Agent, Social Media Agent, Content Agent, and Customer Service Agent.
- Breeze Copilot: A conversational, text-based AI companion that allows human users to query their HubSpot data, generate content summaries, and execute CRM updates using natural language.
- Breeze Intelligence: A built-in data enrichment and intent engine that automatically sweeps public webspheres to populate company profiles, fill missing form data, and surface buyer intent signals.
- Open Platform Architecture: Built-in support for the Model Context Protocol (MCP), allowing external LLMs like Claude, ChatGPT, or Gemini to connect directly to the HubSpot data model via secure server protocols.
What does HubSpot Breeze need to work from a data property perspective?
To work effectively without stalling, HubSpot Breeze requires fully structured property definitions, standardized picklist drop-downs, and a data completeness score exceeding 95% across all core CRM objects.
Breeze agents read property values to analyze context, determine segment routing, and personalize autonomous outreach. If your data model contains empty or unstandardized fields, the agent will stall or produce inaccurate outputs. Prior to activation, you must verify:
- Property Standardization: Free-text properties used for critical segmentation (such as Lifecycle Stage, Industry, or Region) must be converted into strict dropdown select options.
- Enrichment Integration: Ensure Breeze Intelligence or external data tools are mapped to populate firmographic data points before the prospecting or routing agents are activated.
- Value Consistency: Eliminate competing or duplicate custom properties; if sales teams use one custom field for deal qualification while marketing uses another, the agent cannot build a reliable reasoning path.
- Historical Accuracy: Clear out legacy or obsolete property values that could distort the agent’s understanding of account performance history.
Why are HubSpot object associations critical for Breeze agent performance?
HubSpot object associations are critical for Breeze agents because the platform’s relational data model determines how an autonomous agent maps context across contacts, companies, deals, and tickets.
A human sales rep can manually click through an account history to piece together a customer’s relationship with a brand. A Breeze agent, however, reads your database strictly through established backend association rules.
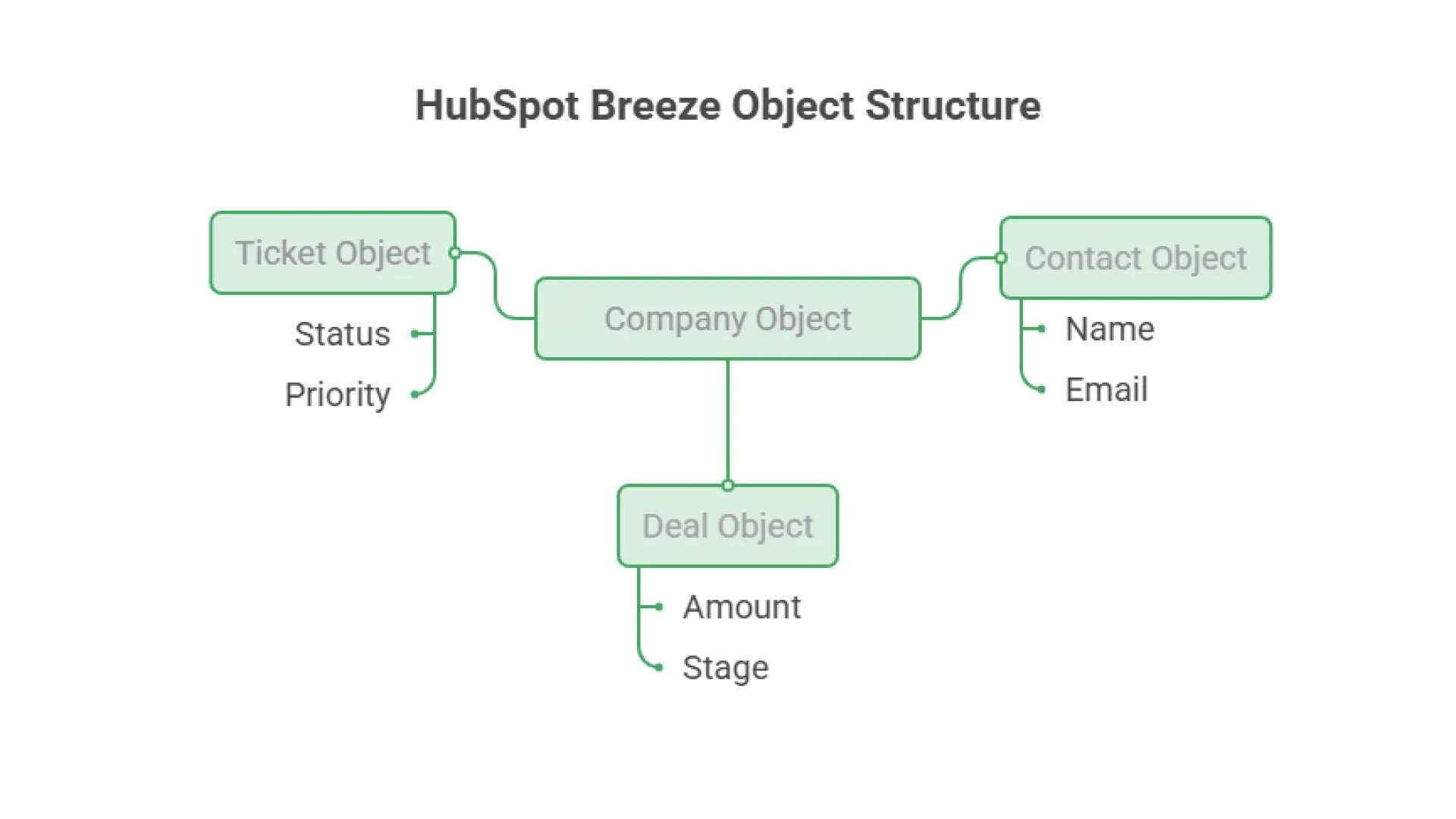 If a contact record is unassociated with its parent company, or a customer service ticket floats independently of its related deal, a Breeze agent will operate with a fractured view of the customer journey. For example, the Customer Service Agent could accidentally trigger a transactional sequence on an account with an active churn ticket, creating a highly disruptive customer experience.
If a contact record is unassociated with its parent company, or a customer service ticket floats independently of its related deal, a Breeze agent will operate with a fractured view of the customer journey. For example, the Customer Service Agent could accidentally trigger a transactional sequence on an account with an active churn ticket, creating a highly disruptive customer experience.
Before deploying any agent, you must enforce strict association rules, utilize HubSpot’s association labels, and run automated data audits to ensure cross-object visibility is unbroken.
How do you configure and govern permission scopes for HubSpot Breeze?
HubSpot Breeze permission scopes are configured by applying the principle of least privilege using HubSpot’s native User Permissions, Scoped Roles, and Model Context Protocol (MCP) access tokens.
Breeze agents and conversational interfaces do not possess infinite system access; they inherit the explicit permissions of the user profile or connected service account that initiates them. To build a secure environment, you must execute three governance steps:
- Role-Based Provisioning: Create a dedicated, non-human user seat for your autonomous agent operations, isolating its system actions from your standard team profiles.
- Object-Level Constraints: Restrict the agent’s view, edit, and delete scopes specifically to the objects it needs; for instance, the Social Media Agent should have zero write access to your Deal or Revenue objects.
- MCP Token Management: When utilizing external models via the Model Context Protocol (MCP), ensure that API access tokens are constrained to tightly defined endpoints and monitored for anomalous traffic.
- Approval Gates: Implement manual review workflows within HubSpot for high-stakes agent outputs, such as bulk email sequences or major deal stage modifications.
What is the Model Context Protocol (MCP) and how does HubSpot use it?
The Model Context Protocol (MCP) is an open-standard architecture that allows HubSpot to act as a secure data destination or an external server engine for advanced third-party AI models.
Instead of locking organizations exclusively into one proprietary LLM, HubSpot’s open architecture lets teams connect external intelligence engines like Anthropic’s Claude, OpenAI’s ChatGPT, or Google’s Gemini directly to their Smart CRM data model.
Through MCP, HubSpot standardizes how external models query data records, invoke custom workflows, and maintain security boundaries. This flexibility ensures that as foundational AI models evolve, your enterprise can easily swap or upgrade your underlying reasoning layer without needing to rebuild your entire HubSpot data pipeline or custom CRM integrations from scratch.
How does the rise of “Shadow AI” affect a HubSpot ecosystem?
The rise of Shadow AI affects a HubSpot ecosystem by introducing unmanaged, third-party browser extensions and unauthenticated API connections that quietly scrape data and create unmonitored data silos.
Because HubSpot is built for speed and ease of use, individual marketing or sales reps frequently install unauthorized AI productivity tools or plug-ins to help write copy or summarize records.
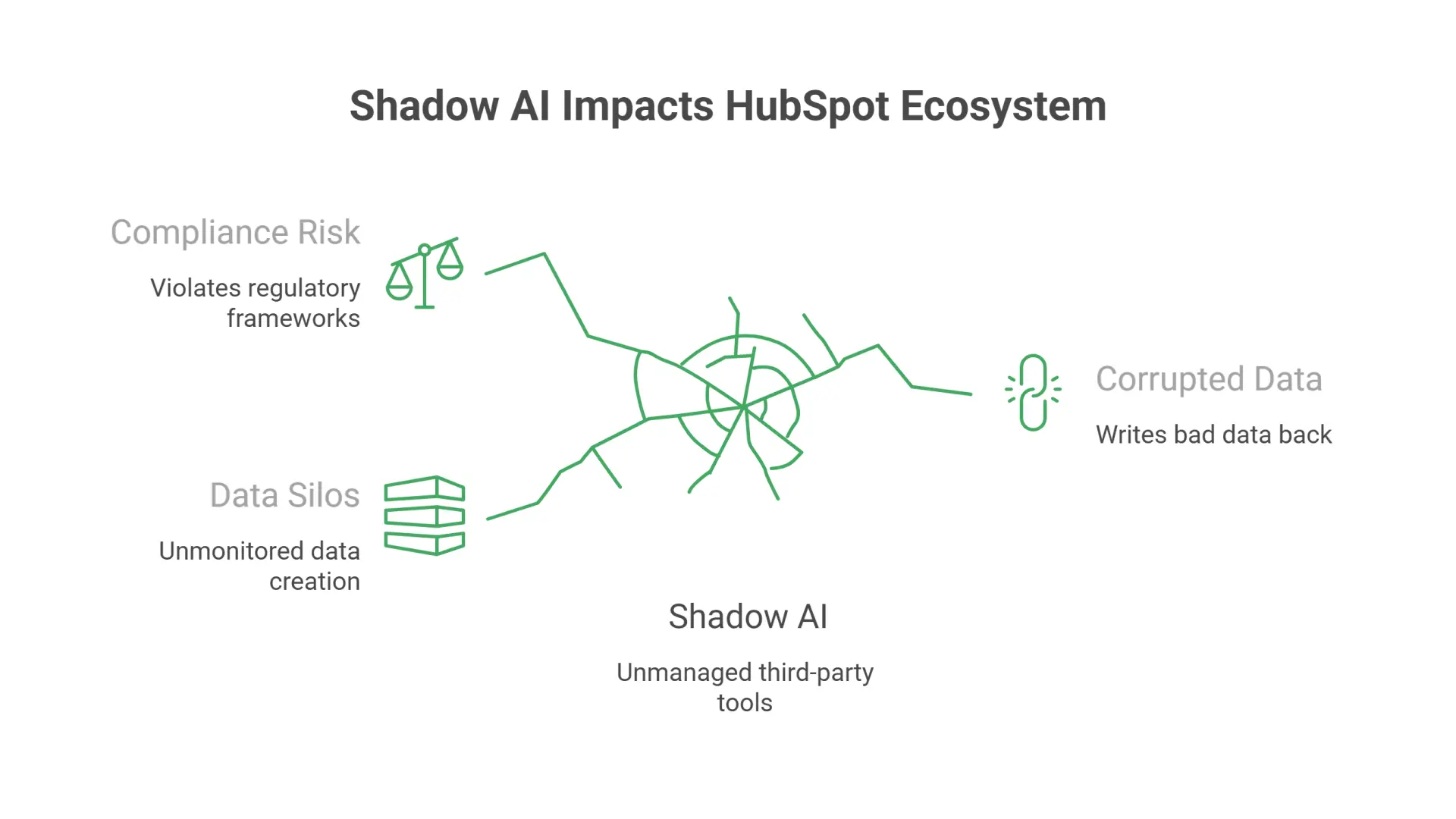 This creates a massive operational and compliance risk. These shadow tools operate outside your central governance framework, do not authenticate through enterprise Single Sign-On (SSO), and often write corrupted data back to your system of record.
This creates a massive operational and compliance risk. These shadow tools operate outside your central governance framework, do not authenticate through enterprise Single Sign-On (SSO), and often write corrupted data back to your system of record.
Furthermore, with upcoming regulatory frameworks like the EU AI Act enforcing strict rules around data tracking, unmanaged shadow tools expose your organization to severe compliance penalties. Overcoming Shadow AI requires running a complete platform audit to surface every active connection and centralizing all automation under an explicit registry.
How should RevOps structure the ultimate pre-flight checklist for HubSpot Breeze?
To ensure a safe deployment, RevOps must structure the ultimate pre-flight checklist for HubSpot Breeze across five core architectural pillars: Data Architecture, System of Record, Governance, Orchestration, and Feedback Loops.
Before allowing any Breeze agent to move into a live production environment, your revenue operations team must verify each of these requirements:
- Data Architecture: Properties are standardized into select menus, duplicate record rates sit firmly below 1%, and historical context data is validated.
- System of Record: A clear, documented data schema defines exactly which system owns the authoritative data signal for every custom and standard property.
- Governance: Dedicated service seats are provisioned, runtime security boundaries are established, and compliance tracking mechanisms are turned on.
- Orchestration: A comprehensive hand-off matrix details exactly when an agent owns a workflow, when it hands data off to another system, and where a human must intervene.
- Feedback Loops: Clear performance loops are engineered into your analytics dashboard to capture exactly how agent actions impact downstream revenue pipeline velocity.
By executing this disciplined sequence, RevOps stops managing isolated tool deployments and steps into its true role as the master systems architect of the enterprise revenue engine.